V svetu, kjer algoritmi odločajo avtentičnost, je nedavni primer knjige “Shy Girl”, ki je bila označena kot UI-generirana in umaknjena s polic knjigarn, sprožil burno razpravo o kredibilnosti detektorjev umetne inteligence. A naj gre za “Shy Girl” ali katerokoli drugo delo, vprašanje ni več “je ali ni UI”.
To ni debata o tem, ali je delo ustvaril človek ali stroj. Gre za veliko globlji problem, saj zdaj živimo v času, ko mora prava umetnost dokazovati svojo pristnost, namesto da bi preprosto obstajala.
Gre za distopijno realnost, ki jo je težko sprejeti. Avtorji, umetniki in ustvarjalci se znajdejo v položaju, kjer so njihova dela, ki so jih ustvarili z lastnimi rokami in možgani, postavljena pod vprašaj. V kolikor je neko delo dejansko človeško, je hkrati hitro in enostavno izpodvrženo temu, da je plod umetne inteligence. In ravno v tej preprostosti tiči nevarnost.
Problem lažnih pozitivnih rezultatov
Študije so več kot jasne: UI detektorji niso zanesljivi. Raziskave so pokazale, da lahko ti sistemi lažno označijo človeško napisano vsebino kot UI-generirano v kar 15–50% primerov, odvisno od orodja in nastavitev. Kako smo torej lahko prišli do točke, ko take nezanesljive mehanizme uporabljamo kot sodnike človeške ustvarjalnosti?
Še bolj zaskrbljujoče je dejstvo, da ti detektorji izkazujejo sistematično pristranskost. Eden od ključnih problemov je ta, da detektorji razmeroma zanesljivo delujejo le na “surovem”, neobdelanem UI izpisu. Ko pa človek svoje delo uredi, polira ali stilizira, kar počne vsak resen avtor, zanesljivost pade.
Visoko besedišče kot “znak UI”
Morda najbolj perverzen vidik te krize je, da se visoko besedišče, natančna gramatika in strukturiran slog pisanja, torej lastnosti, ki so nekoč veljale za znake kakovostnega pisanja, danes interpretirajo kot “sumljive”. Komercialni detektorji namreč analizirajo parametre, kot sta “perplexity” (nepredvidljivost besed) in “burstiness” (variabilnost dolžine stavkov). In kaj se zgodi, ko avtor piše tekoče, dosledno in z bogatim besediščem?
Detektor to označi kot UI.
Študija Stanfordove univerze je pokazala, da so detektorji več kot 60% esejev neangleških govorcev (TOEFL) označili kot UI-generirane, medtem ko so bili lažni alarmi pri ameriških učencih skoraj nični. Podobno so izpostavljeni tudi nevrodivergentni posamezniki in tisti, čigar delo je bilo lektorirano ali optimizirano za berljivost.
Za detekcijo UI potrebujemo UI
Paradoksalno je, da je edini način, da “dokažeš”, da delo ni UI-generirano, ta, da uporabiš prav tako nezanesljive UI detektorje. Uporabljamo torej umetno inteligenco, da bi odkrili umetno inteligenco.
Ti sistemi niso pravosodni organi; so statistični modeli, ki delujejo na podlagi verjetnosti. OpenAI je svoj lastni detektor že leta 2023 umaknil zaradi nezadostne natančnosti. Kljub temu se zanašamo na orodja, katerih razvijalci sami priznavajo omejitve.
Kot ugotavlja raziskava Merlin UI na podlagi 2.3 milijona skeniranj, detektorji dosegajo približno 91-odstotno natančnost. To pomeni, da je od 100.000 pregledanih esejev 4.500 lažno označenih kot UI. V absolutnih številkah to pomeni tisoče napačno obtoženih posameznikov.
Sprememba pisanja, da ugodimo strojem
Posledica? Vedno več ljudi, tako študentov, kot drugih piscev spreminja svoj naravni slog pisanja. Izogibajo se določenim besedam (denimo “delve”, “tapestry”, “nuanced”, saj so postale rdeče zastavice), poenostavljajo stavčne strukture, vnašajo namerne “napake”, da bi zadovoljili algoritme.
To pa je absolutno ironično in se razivja v pravo kulturno katastrofo. Mladi pisci se učijo, da je dobro, strukturirano, bogato pisanje “kaznivo”. Norma postaja osiromašen jezik, ki se izogiba vzorcem, ki jih stroj prepoznava kot “človeške”. Namesto da bi dvigovali standarde, jih nižamo, da bi zadovoljili nezanesljive algoritme.
Distopija, ki jo živimo vsak dan
Zveni distopijsko? Morda. A to ni več znanstvena fantastika. Živimo v času, ko mora pisatelj dokazovati, da je sam napisal svoje besedilo, in kjer mora umetnik dokazovati, da je sam naslikal svojo sliko. To je čas, kjer je domneva nedolžnosti zamenjana z domnevo krivde.
Če je sum dovolj, da se knjiga umakne s polic, brez trdnih dokazov, zgolj na podlagi izpisa nezanesljivega algoritma, potem smo stopili na nevarno pot. Kdo bo naslednji? Katero delo bo jutri označeno kot “UI”? In kako bo njegov avtor, ki je morda porabil mesece ali leta za ustvarjanje, sploh lahko dokazal svojo nedolžnost?
Oscar Wilde je uporabljal UI?
Da bi bolje razumeli, kako problematično je dokazovanje z uporabo umetne inteligence, sem se zatekla k preizkusu na znanem klasičnem literarnem delu. S spleta sem vzela odlomek iz romana Slika Doriana Graya Oscarja Wilda in ga vstavila v tri različne algoritme za preverjanje UI. Izid? Vsi trije so z več kot 91‑odstotno gotovostjo sklenili, da gre za umetno generirano besedilo.
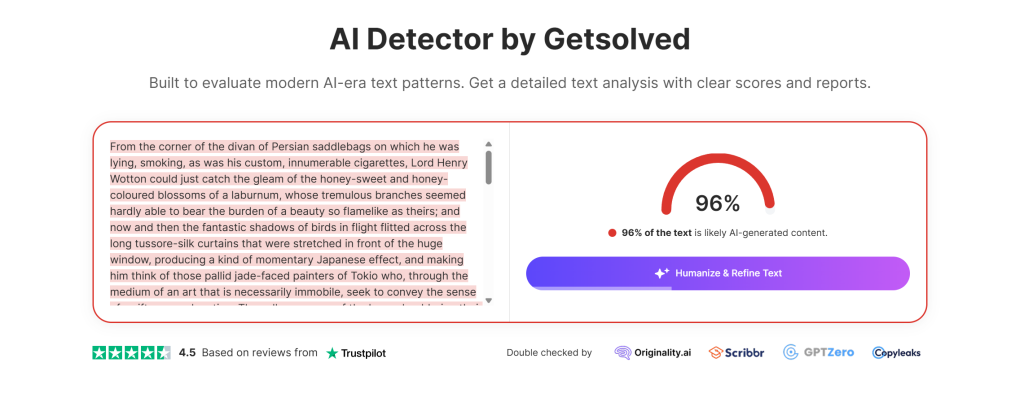
Možn sta zgolj dve razlagi. Prva: Oscar Wilde je že v poznem 19. stoletju uporabljal umetno inteligenco in bil tehnološko daleč pred svojim časom. Druga, rahlo bolj verjetna: sami algoritmi so popolnoma sporni.
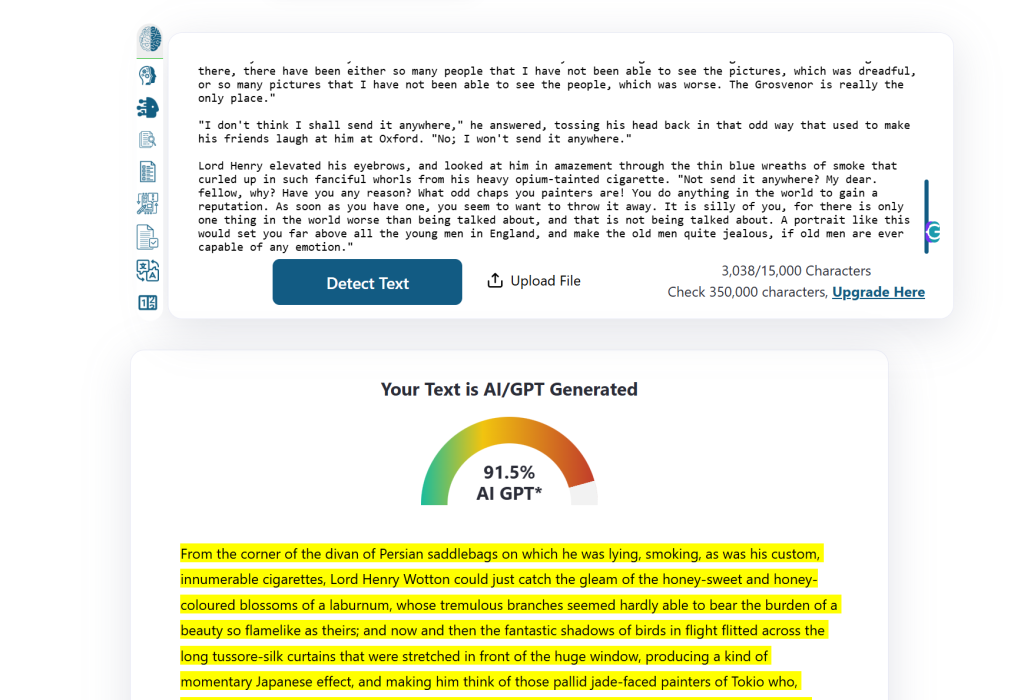
A s tem nisem zaključila. Želela sem preveriti tudi svoje lastno akademsko delo iz leta 2021. Rezultat? Prav tako je bilo označeno kot UI, sicer z nekoliko nižjo stopnjo gotovosti kot Wildeovo delo, kar pomeni le to, da je bilo moje pisanje (žal) slabše od njegovega.
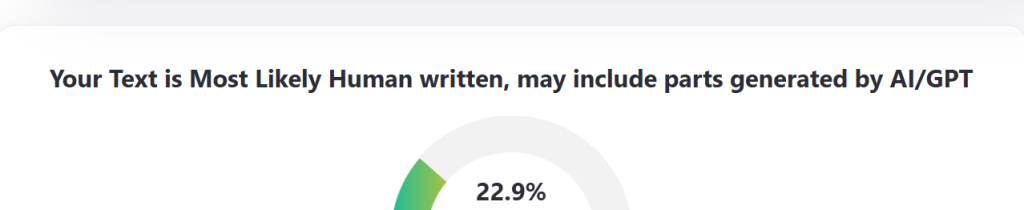
Stroka je že zdavnaj opozorila: UI detektorji niso zanesljivi kot edini dokaz . A kljub temu se vanje zanašamo. In dokler tega ne spremenimo, bo vsak avtor, ki piše dobro, jasno in prečiščeno, potencialna žrtev.
Kriza je tu. Vprašanje je le, kako smo lahko dovolili, da stroji odločajo o vrednosti človeške ustvarjalnosti in to tako nezanesljivo?